Updates
| # | Total |
|---|---|
| IDs searched | 11,954,116 |
| IDs being used by LitScan | 11,028,526 |
| Unique RNA sequences | 4,938,124 |
| Articles found | 1,044,729 |
RNAcentral LitScan is a new text mining pipeline that connects RNA sequences with the latest open access scientific literature. LitScan uses a collection of identifiers (Ids), gene names, and synonyms provided to RNAcentral by the Expert Databases to scan the papers available in Europe PMC and keep the publications linked to RNAcentral entries as up-to-date as possible.
LitScan boasts a user-friendly interface, allowing users to easily filter papers based on various facets such as identifier, article type, the paper section where the ID is located, mentioned organism, journal, and year.
For example, lncRNA THRIL is also known as Linc1992. Using LitScan, the corresponding RNAcentral entry includes papers about THRIL, Linc1992, and even NR_110375 which is another Id for the same gene:
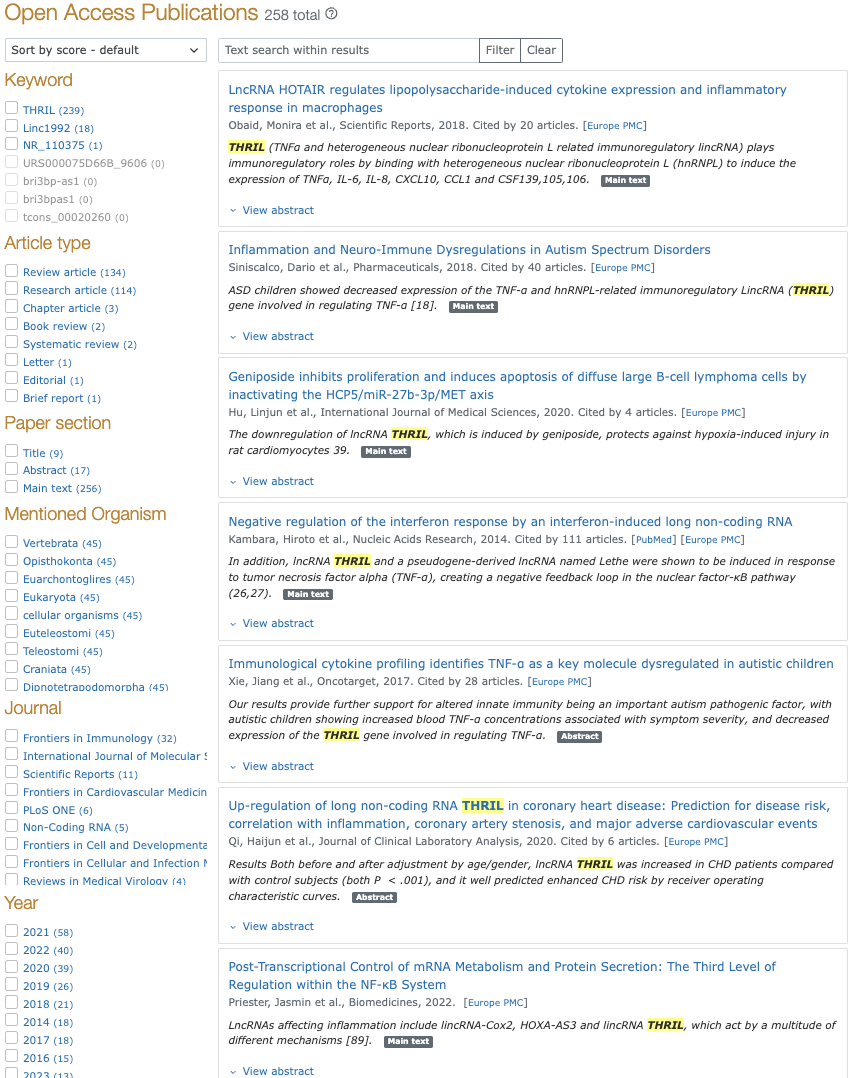
LitScan is under active development and more sequences will be associated with scientific publications in the future.
Browse all sequences with publications
The LitScan widget is implemented as an embeddable component that can be used by any Expert Database or any other website. LitScan has already been deployed on the Rfam website (for example, see the SAM riboswitch page).
Find out more about how to integrate this widget into your website.
A list of RNA Ids provided by the Expert Databases is used to search for open access articles in Europe PMC. The search is performed in two steps:
Search Europe PMC's RESTful WebService for articles that contain an RNA Id anywhere in the text.
The following query is used:

where
"id" is the Id used in the search("rna" OR "mrna" OR "ncrna" OR "lncrna" OR "rrna" OR "sncrna") is used to filter out possible false positivesIN_EPMC:Y means that the full text of the article is available in Europe PMCOPEN_ACCESS:Y it must be an Open Access article to allow access to the full contentNOT SRC:PPR cannot be a Preprint, as preprints are not peer-reviewedAnalyse the full text of the matching articles using regular expressions to locate the Ids within the article's title, abstract, or body. From the article that contains the exact Id, LitScan extracts a sentence with the Id and other relevant information, such as title, authors, journal, etc.
The article will be displayed in the results if the Id is found in both steps.
A search on EuropePMC for the microRNA precursor dme-bantam ID yielded 13 results as of October 2023.
However, the second step finds the exact string dme-bantam only in 4 articles, while the other 9 mention
dme-bantam-3p and/or dme-bantam-5p and appear on the corresponding mature microRNA pages.
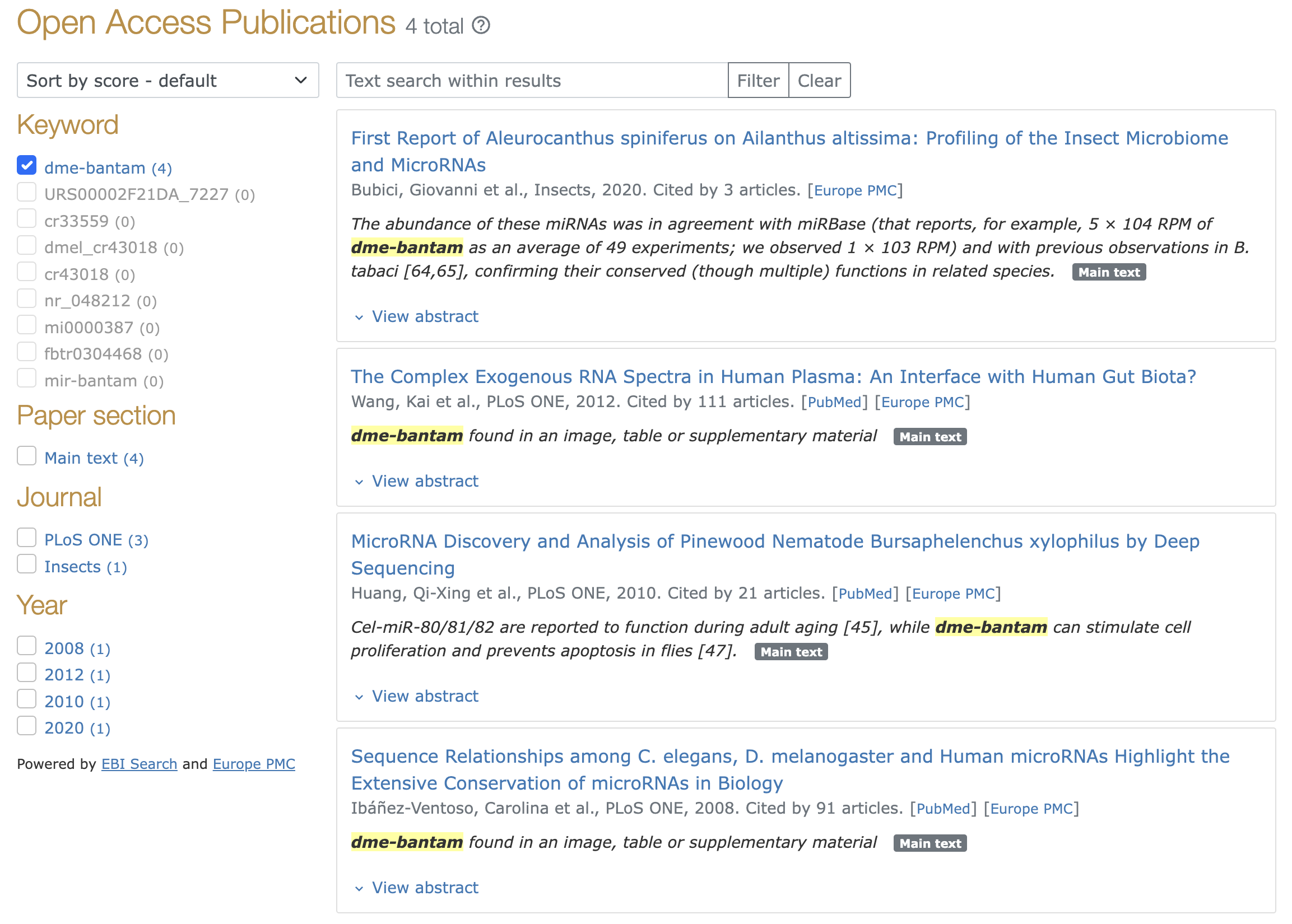
The publications are updated on an ongoing basis.
The citation counts per paper shown by the widget may differ from the counts displayed in Google Scholar, Web of Science or Scopus, as Europe PMC does not have access to the same content as these resources. However, highly cited articles in Europe PMC correlate with highly cited papers on other platforms. Find out more about the Europe PMC citation network.
If your article is found in Europe PMC but not in RNAcentral, this could be due to the following reasons:
The article was recently published and has not yet been imported into LitScan
in this case, it may only be a matter of time before your article is listed in RNAcentral
The article does not have any exact Id used in the searches
new ids will be scanned on an ongoing basis and the article will be included in the near future
Your article is not Open Access in Europe PMC
unfortunately there's nothing we can do in this case as we do not have access to the article
Note that searching for Ids with special characters may sometimes return articles unrelated to the search terms due to the use of the standard Solr tokenizer in the Europe PMC API that treats whitespaces and special characters as delimiters. This is why the search is performed in two steps as regular expressions ensure that only articles containing the exact term are used.
To prevent false positive matches, we compare RNA Ids against a corpus of common English words to exclude Ids like hairpin, nail, digit, or eric that may correspond to non-RNA entities.
The organisms listed in the Mentioned Organisms facet were extracted from the ORGANISMS project and may not be entirely accurate. Find out more about the ORGANISMS project in this paper.
The list of Ids can be accessed programmatically. An example Python script to get a list of ids is available below: